ResNet
A synopsys of seminal reseach paper "ResNet".
The Problem with Depth!
This was the time when after the success of AlexNet on ImageNet data, people started building deeper and deeper network and every time someone managed to build a big network, accuracy on Imagenet data was increased a bit. But this happiness didn’t last long and there was a bottleneck while creating a more deeper network.
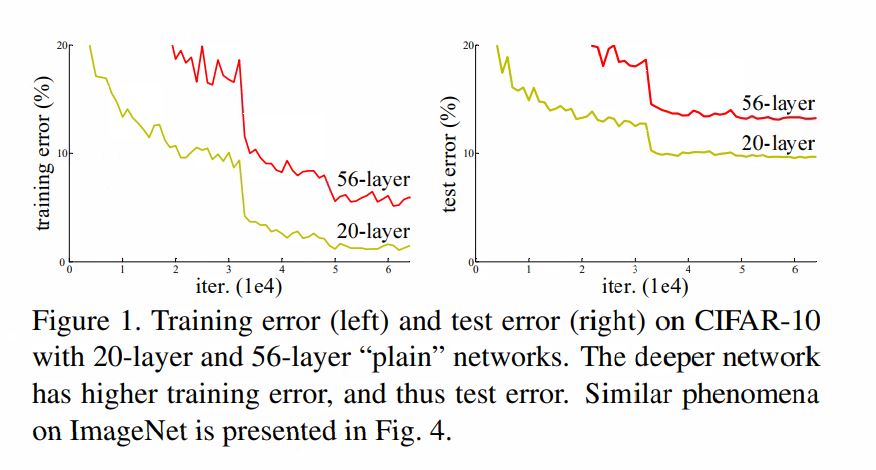
As you can increase the depth of neural network, you can make it better in term of generalization and you can reach lower training loss but optimizing this network was hard. Problem of vanishing/exploding gradients, which hamper convergence from beginning, though it was addressed by introducing batch normalization (in paper they called as normalized initialization and intermediate normalization). When deeper networks are able to start converging, a degradation problem has been exposed: with the network depth increasing, accuracy gets saturated (which might be unsurprising) and then degrades rapidly. Unexpectedly, such degradation is not caused by overfitting, and adding more layers to a suitably deep model leads to higher training error as observerd that a 20 layer deep network was better in term of test and train accuracy than its 56 layre counterpart. The result of CIFAR-10 data has been shown in this picture.
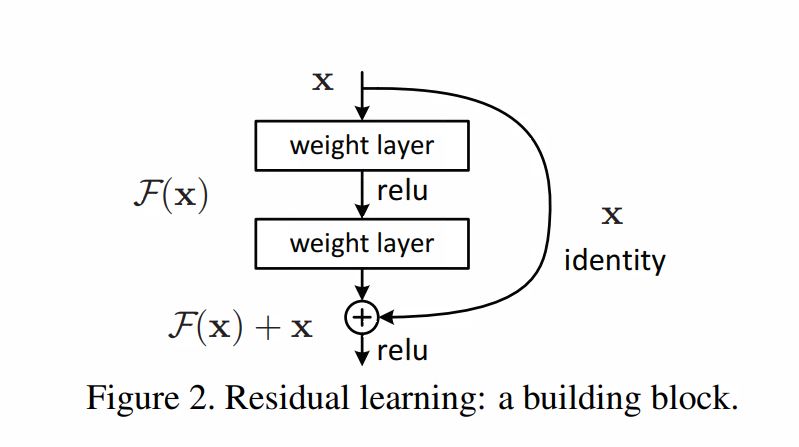
Solution came as Identity mapping
The degradation (of training accuracy) indicates that not all systems are similarly easy to optimize. Let us consider a shallower architecture and its deeper counterpart that adds more layers onto it. There exists a solution by construction to the deeper model: the added layers are identity mapping, and the other layers are copied from the learned shallower model. The existence of this constructed solution indicates that a deeper model should produce no higher training error than its shallower counterpart. But experiments show that our current solvers on hand are unable to find solutions that are comparably good or better than the constructed solution (or unable to do so in feasible time).